Représentativité d'un échantillonnage

Je veux déterminer une prévalence.
:palm_tree: Par exemple, la prévalence des arbres en période de fructification dans une forêt.
:microbe: Ou bien la prévalence d’une maladie / caractéristique dans une population cible donnée : les abeilles à la Réunion, les humains qui fument ou qui font un sport en particulier.
:x: Je n’ai pas de sous. Je n’ai pas beaucoup de temps non plus. Alors, je ne peux pas aller voir tous les arbres de la forêt, je ne peux pas analyser toutes les ruches de l’île, ni interroger tous les humains qui font de l’aqua-poney (quoique… il n’y en a peut-être pas tant que ça, c’est jouable !)
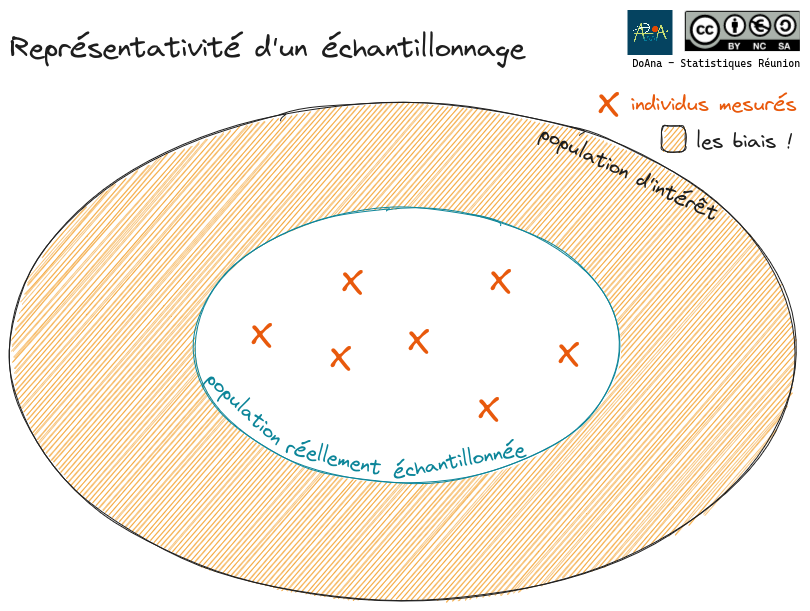
Qu’à cela ne tienne ! Je choisis d’échantillonner ma population d’intérêt, c’est-à-dire de n’en regarder qu’une partie, choisie de telle sorte que je puisse ensuite généraliser mes résultats à la population d’intérêt.
Bon, mais je n’ai toujours pas plus de sous que depuis le dernier paragraphe. Je n’ai pas les moyens de l’INSEE qui parviennent à calculer un “degré de représentativité” de chaque réponse récoltée (ça s’appelle des poids). En fait, j’ai juste un simple formulaire en ligne ou en papier.
:thinking: Qu’est-ce que j’en fais ? Où je l’envoie ? Comment faire pour choisir mes individus (arbres, ruches ou humains) ?
Échantillonnage biaisé
Parce que le risque, c’est de me retrouver avec un échantillonnage biaisé. Quoi quoi quoi ?
Exemple de biais (j’invente hein, ho, bon… certaines choses sont du vécu) :
- la forêt est impénétrable, je n’ai regardé que les arbres en bordure de chemin
- les fruits sont tout petits / très hauts dans la canopée, je ne suis pas sûre de les voir systématiquement
- on était deux à prendre les données et l’autre personne a un daltonisme non diagnostiqué et il allait beaucoup plus vite que moi, il a mesuré 2 fois plus d’arbres que moi
- je visite les ruches déclarées officiellement, mais pas les autres !
- je récolte les données sur 3 mois en commençant par le nord de l’île, seulement la maladie s’est propagée ultra vite et à la fin de la récolte des données (dans le sud donc), le nord a été contaminé entre-temps
- la technique de détection de la maladie (PCR par exemple) n’est pas absolument fiable (ça n’existe pas, en fait, une mesure 100% fiable)
- les humains qui ont bien voulu répondre sont les humains qui répondent aux questionnaires (et pas les autres !)
- et puis, d’ailleurs, les humains qui ne vont pas sur les réseaux sociaux ou à des événements sociaux (que j’avais choisi justement pour distribuer mes questionnaires) n’ont pas répondu non plus, puisqu’ils n’ont pas vu passer le questionnaire
- certains humains n’étaient pas en forme et ont répondu seulement à une partie des questions
- les questions n’ont pas été comprises de la même manière par tous les répondants
Si j’ai un échantillonnage biaisé, alors je ne peux pas généraliser mes résultats à toute ma population d’intérêt. N’est-ce pas ?
Dans ce cas, ce qu’il se passe, c’est que la population réellement observée n’est pas tout à fait exactement la population d’intérêt choisie au départ.
Les données sont déjà récoltées
:dart: Ce que je peux faire, c’est estimer un niveau de confiance de la représentativité de mon échantillon dans la population d’intérêt.
Le niveau est bas si les biais identifiés ont une forte probabilité d’influer sur les résultats (et le pire, c’est que ce niveau est biaisé lui aussi, vu qu’il va dépendre de l’expertise de la personne qui le choisit. Qui a dit que la science, c’était neutre ?).
:speak_no_evil: Bon alors, voilà… la boulette. Les données sont déjà récupérées et/ou je n’ai aucune idée pour m’extraire de ces biais (pas de sous, pas de temps : place au système D !) Alors, comment faire pour augmenter ce niveau de confiance ?
Je vois une première possibilité
:scroll: Si, par ailleurs (dans la littérature), j’ai des informations concernant toute la population d’intérêt (de manière fiable, bien sûr), alors je peux comparer ces informations avec mes propres résultats (par exemple les données socio-démographiques pour les humains, comme le sexe, la distribution des âges, le niveau social etc.). En supposant qu’ils soient suffisamment proches, alors je peux augmenter ma confiance dans la représentativité de mon échantillon. Ce n’est pas parfait, mais c’est déjà ça.
:bulb: Et si les informations sont totalement différentes (argh), alors il est intéressant de se questionner pour savoir quel(s) biais est le plus responsable et comment le prendre en compte efficacement pour la prochaine fois. (Le principe de l’expérimentation, c’est bien d’apprendre de ses erreurs ;) ) Il existe également des méthodes mathématiques pour corriger (partiellement) le biais à l’aide de données non biaisées indépendantes pour peu qu’il ait des variables auxiliaires en commun [exemple : Beaumont, 2021]. Perso, je ne sais pas (encore) faire ça.
:speaking_head: Une seconde possibilité, c’est de faire très très très attention dans la formulation de l’interprétation des résultats. Et de biiiien parler des biais d’échantillonnage identifiés dans la discussion !
Réfléchir au moment de la mise en place du protocole
:money_mouth_face: Bon, ok, admettons que j’ai UN PEU de sous, c’est quoi les méthodes d’échantillonnage qui pourraient être moins biaisées ?
:brain: Déjà, je prends le temps AVANT de récolter les données pour utiliser mon cerveau et imaginer les biais possibles.
:handshake: Parfois, mon expérience ne permet pas de tout anticiper et je peux me planter, mais il y a peut-être d’autres personnes qui se sont déjà plantées avant moi et qui ont de l’expérience, je peux aller leur demander. En général, les gens sont contents de parler de leurs problèmes, surtout si c’est utile pour quelqu’un d’autre !
PISTES pour prendre en compte les biais totalement imaginaires (lol) ci-dessus :
| Biais | Pistes |
|---|---|
| la forêt est impénétrable, je n’ai regardé que les arbres en bordure de chemin | les arbres dans leur forêt, ils ne bougent pas trop. Un quadrillage en plusieurs secteurs équivalents (en termes de densité, altitude, surface, c’est à moi de faire ce choix !). Un nombre d’arbres à regarder par secteur (le même pour chacun ou bien proportionnel à la surface, c’est mon choix !) |
| les fruits sont tout petits / très hauts dans la canopée, je ne suis pas sûre de les voir systématiquement | choisir plusieurs méthodes de mesures pour faire des recoupages (compter les fruits visibles en l’air, utiliser un drone pour ceux en hauteur, compter les fruits tombés par terre… c’est mon choix !). |
| on était deux à prendre les données et l’autre personne a un daltonisme non diagnostiqué et il allait beaucoup plus vite que moi, il a mesuré 2 fois plus d’arbres que moi | répartir aléatoirement les secteurs entre les observateurs ou bien utiliser le binôme comme une équipe qui échantillonne tout ensemble, mais se répartit les tâches (perso, je conduis le drone, toi tu remplis les cases) |
| je visite les ruches déclarées officiellement, mais pas les autres ! | là, c’est chaud, je peux envoyer mon drone en recherche de ruchers marrons (illégaux) en douce ? Je peux émettre l’hypothèse que la maladie n’est pas sélective entre abeille légale ou non et me dire que ce biais n’empêchera pas de répondre correctement à la question de recherche. C’est mon hypothèse ! |
| je récolte les données sur 3 mois en commençant par le nord de l’île, seulement la maladie s’est propagée ultra vite et à la fin de la récolte des données (dans le sud donc), le nord a été contaminé entre temps | je récolte les données sur une durée plus courte ou bien je choisis un ordre aléatoire de mes visites |
| la technique de détection de la maladie (PCR par exemple) n’est pas absolument fiable (ça n’existe pas, en fait, une mesure 100% fiable) | je trouve dans le mode d’emploi quelle est la précision de la mesure et je la prends en compte dans la formulation de mon hypothèse H0 (les moyennes sont égales… oui, ça veut dire quoi égales ?) ou alors plusieurs répétitions de la mesure |
| les humains qui ont bien voulu répondre sont les humains qui répondent aux questionnaires (et pas les autres !) | à l’INSEE, ils contactent par téléphone les gens choisis par leur adresse postale, même ça, c’est biaisé, puisqu’il faut bien trouver le numéro de téléphone de la personne. Bref, je ne suis pas l’INSEE, ce biais-là, il est intrinsèque (et ça ne fait pas de mal de le mentionner quand même). |
| et puis, d’ailleurs, les humains qui ne vont pas sur les réseaux sociaux ou à des événements sociaux (que j’avais choisi justement pour distribuer mes questionnaires) n’ont pas répondu non plus, puisqu’ils n’ont pas vu passer le questionnaire | ajouter une question et demander la provenance du questionnaire (par quel biais la personne l’a obtenu) pour ensuite potentiellement prendre en compte cette info pour l’interprétation |
| certains humains n’étaient pas en forme et ont répondu seulement à une partie des questions | je me résigne et supprime leurs réponses. J’anticipe et me fixe un objectif de réponse supérieur à 10% de l’objectif idéal (en termes de test de puissance, mais non… c’est quoi encore ce truc ?) |
| les questions n’ont pas été comprises de la même manière par tous les répondants | je fais un petit panel test de gens pas du tout éduqués à ma question de recherche et je suis présente quand ils répondent et leur demande comment ils ont choisi leurs réponses. Je peux ajuster ainsi la formulation des questions avant de lancer la campagne. |
:mountain_snow: Bon, et sinon, il existe des techniques d’échantillonnage éprouvées et approuvées. Elles diffèrent un peu (beaucoup) selon le champs d’application et les contraintes associées (une collègue est allée échantillonner les lynx dans les Alpes, je ne l’envie pas).
Prendre conscience et exprimer nos choix
:beach_umbrella: Donc, en fait, juste… La science, ce n’est pas neutre. Ne pas dire explicitement quels sont nos choix, notre population réellement échantillonnée et nos hypothèses a priori sous prétexte d’une science “idéalement” neutre, c’est vraiment se mettre la tête dans le sable.
:arrow_right: :new: :arrow_left: Voilà pourquoi j’aimerais (j’ordonne, j’exige) qu’il y ait plus de soin et d’attention portée sur le début des projets de recherche. C’est mon leitmotiv et je ne vais pas te lâcher avec ça. Mouhaha :smiling_imp:
Anna Doizy
Chercheuse, consultante et formatrice freelance
Libre comme l’R
Méthodologie scientifique et analyses de données statistiques